GTU Operating System Summer 2021 Paper Solution
Download Question Paper : click here
Q.1
(a) Define the essential properties of the following types of operating systems:
(1) Batch
- Non-interactive execution of jobs.
- Offline processing of input data.
- Job scheduling algorithms for resource allocation.
(2) Time-sharing
- Interactive computing for multiple users.
- Time-slicing technique for task execution.
- Multitasking support for concurrent execution.
(3) Real-time
- Deterministic response based on task deadlines.
- Categorization into hard real-time and soft real-time systems.
- Resource management to meet timing requirements.
(b) What are the advantages of multiprogramming?
The advantages of multiprogramming include:
- Increased CPU Utilization: Multiprogramming allows multiple programs to be loaded into memory simultaneously. This enables the CPU to switch between different programs when one is waiting for I/O or other operations, effectively utilizing the CPU’s idle time.
- Enhanced Throughput: With multiprogramming, multiple programs can be executed concurrently, leading to improved overall system throughput. As one program waits for I/O or other operations, the CPU can quickly switch to another ready program, keeping the system productive.
- Improved Responsiveness: Multiprogramming enhances system responsiveness by reducing the waiting time for users. Users can interact with the system even while other programs are executing, providing a smoother and more interactive computing experience.
- Efficient Resource Utilization: By allowing multiple programs to share system resources such as memory, CPU, and peripherals, multiprogramming optimizes resource utilization. This results in better overall system performance and cost-effectiveness.
(c) What is the thread? What are the difference between user-level threads and kernel supported threads? Under what circumstances is one type “better” than the other?
A thread is a lightweight unit of execution within a process. It represents an independent sequence of instructions that can be scheduled and executed by the operating system.
Differences between User-level threads (ULTs) and Kernel-supported threads (KLTs):
- Management: ULTs are managed by user-level thread libraries and do not require kernel involvement for thread management. On the other hand, KLTs are managed directly by the operating system kernel.
- Thread Control Block (TCB): Each ULT has its own TCB, which is maintained by the user-level thread library. KLTs, however, have their TCBs managed by the kernel.
- Blocking: If a ULT performs a blocking operation, such as I/O, it blocks the entire process since the kernel is unaware of the ULTs. In contrast, if a KLT blocks, the kernel can schedule another thread for execution.
- Context Switching: Context switching between ULTs is faster as it only involves user-level operations. Context switching between KLTs involves both user-level and kernel-level operations, making it comparatively slower.
- ULTs are generally more lightweight and provide faster context switching, making them suitable for applications that require frequent thread creation, synchronization, and communication. They are also more flexible and can be customized based on application needs.
- KLTs, being managed by the kernel, provide better concurrency control and can handle blocking operations more efficiently. They are suitable for applications that heavily rely on I/O or require fine-grained control over thread behavior.
Q.2
(a) What is Process? Give the difference between a process and a program.
Process: A process is an instance of a running program that has its own memory, resources, and execution context, and can perform tasks and interact with other processes.
| Process | Program |
|---|---|
| Represents an executing instance of a program | Refers to a set of instructions or code |
| Has its own memory and resources | Does not have its own memory and resources |
| Can be scheduled and executed by the operating system | Cannot be scheduled or executed directly by the operating system |
(b) What is Process State? Explain different states of a process with various queues generated at each stage
Process State: Process state refers to the current condition or status of a process in an operating system. It represents the stage of execution that a process is currently in.
Process State and Queues:
- New: The process is in the new state and resides in the job queue, waiting to be admitted into the system.
- Ready: The process is in the ready state and resides in the ready queue, waiting to be assigned to a processor for execution.
- Running: The process is in the running state and actively executing its instructions. Typically, there is no dedicated running queue as only one process can run on a single processor at a time.
- Blocked: The process is in the blocked state, waiting for an event or resource to become available. It resides in the blocked queue until the desired event or resource is ready.
- Terminated: The process has completed its execution or has been explicitly terminated. It is removed from the system.
(c) Write a bounded-buffer monitor in which the buffers (portions) are embedded within the monitor itself.
also known as (Producer Consumer Problem)
- A monitor is a collection of procedures, variables, and data structures that are all grouped together in a special kind of module or package.
Producer Consumer Bounded Buffer Problem using Monitor (Hoare’s approach)
monitor boundbuffer; //start of monitor
char buffer[N]; // N slots
int nextin,nextout; // buffer pointers
int count; // number of items in buffers
int notfull, notempty; // condition variables
void append(char a) // monitor procedure public
{
if (count == N) //if buffer is full
cwait(notfull); // avoid overflow
buffer[nextin]=a;
nextin=(nextin+1)%N;// next slot in buffer
count++; // An item is added in buffer
csignal(notempty); //resume if consumes waiting
}
void take(char a) // monitor procedure public
{
if (count==0) // if buffer is empty
cwait(notempty); // avoid underflow
a = buffer[nextout];
nextout = (nextout+1)%N; //next slot in buffer
count --; // An item is removed from buffer
csignal(notfull); // resume any waiting producer
}
{ //initialization
nextin=nextout=count=0; //initially buffer empty
}
void main()
{
pasbegin(producer, consumer);
}note : above provided code is pseudocode.
OR
(c) What is Semaphore? Give the implementation of Readers-Writers Problem using Semaphore.
Semaphore is a synchronization primitive used in concurrent programming to control access to shared resources. It is a non-negative integer variable that can be accessed atomically. Semaphores are typically used to solve critical section problems and coordinate access to resources among multiple threads or processes.
Here’s an implementation of the Readers-Writers Problem using semaphores:
typedef int semaphore;
semaphore mutex = 1; //control access to reader count
semaphore db = 1; //control access to database
int reader_count = 0; //number of processes reading database
void Reader(void) {
while (true) {
wait( & mutex); //gain access to reader count
reader_count = reader_count + 1; //increment reader counter
if (reader_count == 1) //if this is first process to read DB
wait( & db) //prevent writer process to access DB
signal( & mutex) //allow other process to access reader_count
read_database();
wait( & mutex); //gain access to reader count
reader_count = reader_count - 1; //decrement reader counter
if (reader_count == 0) //if this is last process to read DB
signal( & db) //leave the control of DB, allow writer process
signal( & mutex) //allow other process to access reader_count
use_read_data(); //use data read from DB (non-critical)
}
}
void Writer(void) {
while (true) {
create_data(); //create data to enter into DB (non-critical)
wait( & db); //gain access to DB
write_db(); //write information to DB
signal( & db); //release exclusive access to DB
}
}Q.3
(a) Define the difference between preemptive and nonpreemptive scheduling.
| Preemptive Scheduling | Non-preemptive Scheduling |
|---|---|
| Allows the scheduler to interrupt a running process and allocate the CPU to another process | Does not allow the scheduler to interrupt a running process |
| Priority-based or time-sliced scheduling algorithms are commonly used | Typically uses First-Come-First-Served (FCFS) or Shortest Job Next (SJN) algorithms |
| Provides better responsiveness and fairness in a multi-user or multi-tasking environment | Suitable for simple and single-user systems with less emphasis on responsiveness |
| More complex to implement and requires additional overhead to manage context switching | Less complex to implement and involves minimal overhead in terms of context switching |
(b) What are the Allocation Methods of a Disk Space?
The allocation methods used for disk space management are:
- Contiguous Allocation:
- Each file occupies a contiguous block of disk space.
- Simple and efficient for sequential access.
- External fragmentation may occur if files are deleted or resized.
- Linked Allocation:
- Each file is a linked list of disk blocks.
- No external fragmentation.
- Inefficient for direct access and requires traversal of the linked list for each block.
- Indexed Allocation:
- Each file has an index block that contains pointers to its data blocks.
- Efficient for both sequential and direct access.
- Requires an additional level of indirection and may have internal fragmentation.
- File Allocation Table (FAT):
- Uses a table to map file names to their disk blocks.
- Provides efficient random access and easy file system maintenance.
- Requires a large portion of disk space for the FAT table in large file systems.
(c) What is deadlock? Explain deadlock prevention in detail.
Deadlock is a situation in a multi-process system where two or more processes are unable to proceed because each is waiting for a resource that is held by another process in the same set. It is a state of a system where processes are stuck and cannot continue execution.

https://arctype.com/blog/content/images/size/w1750/2021/02/deadlock.jpeg
Deadlock prevention is to deny at least one of the 4 conditions for deadlock.
Deadlock prevention is a technique used to ensure that a system avoids reaching a deadlock state. It focuses on breaking one or more of the necessary conditions for deadlock to occur. The following methods are commonly used for deadlock prevention:
- Mutual Exclusion:
- Ensure that resources are not shareable and can only be accessed by one process at a time.
- Avoids the possibility of deadlock due to conflicting resource access.
- Mutual exclusion cannot be denied so it is customary to prevent one of the remaining 3 conditions.
- Hold and Wait:
- Processes must request and acquire all required resources before execution.
- Avoids the possibility of deadlock caused by a process holding resources and waiting for others.
- These are basically two implementation:
- The process requests all needed resources prior to its execution
- The process requests resources incrementally during execution but releases all its resources when it encounters denial of one resource.
- No Preemption:
- Resources cannot be forcefully taken away from a process.
- Avoids the possibility of deadlock caused by a process holding resources indefinitely.
- This deadlock condition of no preemption can be denied by allowing preemption, that is done by authorizing the system to revoke ownership of certain resources from blocked process.
- Circular Wait:
- Implement a resource allocation hierarchy to avoid circular dependency.
- Processes request resources in a predefined order, eliminating the circular wait condition.
- If a process P1 has been allocated a resource Ri, then if another process P2 another resource Rj; The resource Rj is allocated to process P2 only if i<j. So, that there is no circular-wait on resources.
OR
Q.3
(a) What are the disadvantages of FCFS scheduling algorithm as compared to shortest job first (SJF) scheduling?
The disadvantages of the First-Come-First-Serve (FCFS) scheduling algorithm compared to the Shortest Job First (SJF) scheduling algorithm are as follows:
- Poor Average Waiting Time: FCFS may lead to a higher average waiting time compared to SJF. If long processes arrive first, shorter processes have to wait for a longer duration, causing increased waiting times.
- Lack of Responsiveness: FCFS is a non-preemptive algorithm, meaning once a process starts executing, it continues until completion. This lack of preemption can result in poor system responsiveness as shorter processes may have to wait for longer processes to finish, even if they are in the queue.
- Inefficiency with Varying Burst Times: FCFS does not consider the burst time or execution time of processes. If a long process arrives early in the queue, it can delay the execution of shorter processes, leading to inefficient resource utilization.
(b) Distinguish between CPU bounded, I/O bounded processes.
- Resource Utilization: CPU-bound processes heavily utilize the CPU, while I/O-bound processes rely more on I/O operations and may have periods of CPU idleness.
- Performance Considerations: CPU-bound processes focus on optimizing CPU utilization, while I/O-bound processes prioritize efficient handling of I/O operations.
- Scheduling Priorities: CPU-bound processes may be prioritized for fair CPU allocation, while I/O-bound processes require efficient I/O scheduling to minimize waiting times.
- Performance Impact: CPU-bound processes can impact system responsiveness and may cause delays in executing other processes, while I/O-bound processes may experience longer execution times due to I/O operation requirements.
(c) What is deadlock? Explain deadlock Avoidance in detail.
Deadlock is a situation in a multi-process system where two or more processes are unable to proceed because each is waiting for a resource that is held by another process in the same set. It is a state of a system where processes are stuck and cannot continue execution.
- The ‘state’ of the system is simply the current allocation of resources to process.
- A ‘safe state’ is one in which all of the processes can be run to completion without deadlock.
- An ‘unsafe state’ is that which is not safe.
Deadlock avoidance:
- Focuses on dynamically analyzing resource allocation requests to determine if they will lead to a deadlock.
- Uses an algorithm to assess safe states and avoid the occurrence of deadlocks.
- Considers resource allocation information, resource availability, and process resource requirements.
- Allows for more flexible resource allocation but requires runtime monitoring and decision-making.
Process information Denial: If a new process requests a resource and if the resources is available, it is allocated to that process otherwise the process is suspended until the active process who has acquired the resource, releases it.
Resource Allocation Denial: The strategy of resource allocation denial referred to as the ‘Banker’s Algorithm’. Banker's algorithm is a deadlock avoidance algorithm. It is named so because this algorithm is used in banking systems to determine whether a loan can be granted or not.
Deadlock avoidance algorithm (Banker’s algorithm):
- Initialize available resources, maximum resource requirements, and currently allocated resources for each process.
- Simulate resource allocation requests and check if granting the request will lead to a safe state.
- If granting the request results in a safe state, allocate the resources and update the available resources.
- If granting the request leads to an unsafe state, deny the request or put the process in a waiting state.
- Continuously monitor resource allocation and dynamically assess if the system remains in a safe state.
Q.4
(a) What is Access control?
Access control refers to the security mechanism that determines and regulates who is granted access to resources, systems, or information within a computing environment. It involves managing and enforcing permissions and restrictions on users, processes, or entities to ensure authorized access and protect against unauthorized access.
Access control involves defining and implementing policies, rules, and mechanisms to govern access privileges, such as read, write, execute, or modify permissions, based on various factors like user identity, roles, groups, or attributes. It helps safeguard sensitive data, maintain system integrity, and prevent unauthorized actions that could compromise the security and confidentiality of resources.
(b) What are Pages and Frames? What is the basic method of Segmentation?
Pages and frames are units of memory used in memory management techniques.
- Pages: In paging, the main memory is divided into fixed-size blocks called pages. These pages are of equal size and represent the logical address space of a process. The size of a page is typically a power of 2, such as 4KB or 8KB.
- The partitions of secondary memory are called as pages.
- Frames: Frames are the corresponding fixed-size blocks in physical memory. They represent the actual physical memory blocks available for allocation. The size of a frame matches the size of a page.
- The partitions of main memory are called as frames.
Segmentation is another non-contiguous memory allocation technique. It is a variable size partitioning scheme.
In segmentation, process is not divided blindly into fixed size pages. Rather, the process is divided into modules for better visualization. secondary memory and main memory are divided into partitions of unequal size.
The partitions of secondary memory are called as segments.
Segments can vary in size and are not required to be of equal size like pages in paging.
(c) Briefly explain and compare, fixed and dynamic memory partitioning schemes.
Fixed Memory Partitioning:
- In fixed memory partitioning, the main memory is divided into fixed-size partitions or blocks.
- Each partition is dedicated to a specific process or job, regardless of its actual memory requirements.
- The number of partitions is predetermined and fixed.
- When a process is loaded into memory, it is assigned to a partition that can accommodate its size.
Dynamic Memory Partitioning:
- In dynamic memory partitioning, the main memory is divided into variable-sized partitions based on the size of the processes.
- The partitions are created and adjusted dynamically based on the memory requirements of the processes.
- When a process is loaded into memory, a partition of an appropriate size is created to accommodate it.
- When a process is terminated or removed from memory, the partition it occupied is freed and can be reused for other processes.
| Fixed Memory Partitioning | Dynamic Memory Partitioning | |
|---|---|---|
| Partition Size | Fixed size partitions | Variable size partitions |
| Number of Partitions | Predetermined and fixed | Adjusted dynamically based on process requirements |
| Internal Fragmentation | Can lead to internal fragmentation | Reduces internal fragmentation by allocating based on requirement |
| External Fragmentation | No external fragmentation | Can lead to external fragmentation over time |
| Memory Utilization | May result in inefficient utilization | Better utilization by allocating based on actual requirements |
OR
Q.4
(a) Explain difference between Security and Protection?
- Security: Security refers to measures taken to protect a system or resources from unauthorized access, damage, theft, or other potential threats. It involves implementing various mechanisms, such as authentication, encryption, firewalls, and access controls, to ensure the confidentiality, integrity, and availability of the system or data.
- Protection: Protection, on the other hand, focuses on the internal mechanisms within an operating system to control access and prevent unauthorized actions. It involves the implementation of access control policies, permissions, and privileges to ensure that only authorized entities or processes can access or modify system resources.
(b) Differentiate external fragmentation with internal fragmentation.
| External Fragmentation | Internal Fragmentation | |
|---|---|---|
| Definition | Free memory blocks are scattered throughout memory, resulting in small pockets of unused space that are not contiguous. | Wasted memory within allocated blocks due to the allocation of larger memory blocks than necessary. |
| Cause | Memory allocation and deallocation of processes. | Memory allocation of fixed-sized blocks, resulting in unused space within allocated blocks. |
| Impact | Reduces overall memory utilization and can lead to inefficient memory management. | Reduces effective memory capacity and can impact system performance. |
| Solution | Compaction or memory compaction techniques can be used to minimize external fragmentation. | Efficient memory allocation strategies, such as dynamic memory allocation, can help minimize internal fragmentation. |
| Example | Allocating variable-sized processes, such as in dynamic memory allocation. | Allocating fixed-sized memory blocks, such as in static memory allocation. |
(c) Explain the best fit, first fit and worst fit algorithm
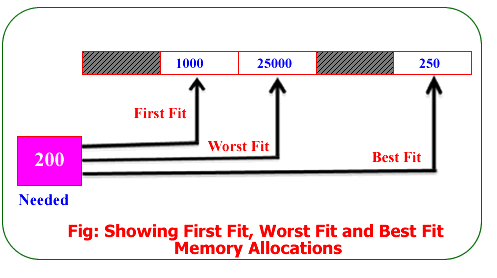
- Best Fit:
- Best Fit algorithm searches for the smallest free partition that can accommodate the incoming process.
- It minimizes external fragmentation by allocating the process to the closest fit in size.
- It traverses the entire free memory list to find the best suitable partition, which can be time-consuming.
- The advantage is that it can reduce wastage of memory by allocating processes efficiently.
- First Fit:
- First Fit algorithm allocates the process to the first available free partition that is large enough to hold it.
- It starts searching from the beginning of the free memory list and allocates the process in the first suitable partition it encounters.
- It is a simple and efficient algorithm but can lead to significant fragmentation over time.
- It quickly finds a suitable partition, making it faster than Best Fit.
- Worst Fit:
- Worst Fit algorithm allocates the process to the largest available free partition.
- It aims to maximize fragmentation by leaving behind larger chunks of free memory.
- It may result in inefficient memory utilization and can be suitable in situations where smaller free partitions are likely to be requested later.
- It requires traversing the entire free memory list to find the largest suitable partition, making it slower than Best Fit and First Fit.
Q.5
(a) Explain the concept of virtual machines
Virtual machines (VMs) are software-based emulations of physical computer systems. They allow for running multiple operating systems and applications simultaneously on a single physical machine. Key points about virtual machines include:
- Virtualization: VMs are created through virtualization technology that abstracts and isolates the underlying hardware resources.
- Hypervisor: The hypervisor, or virtual machine monitor (VMM), manages the virtualization process and sits between the physical hardware and the virtual machines.
- Isolation and Independence: Each virtual machine operates independently, with its own operating system, applications, and resources.
(b) Compare virtual machine and non virtual machine.
| Virtual Machines (VMs) | Non-Virtual Machines | |
|---|---|---|
| Hardware | Utilizes virtualized hardware resources. | Utilizes dedicated physical hardware resources. |
| Isolation | Provides strong isolation between VMs. | Lacks isolation between different software components. |
| Resource Sharing | Allows efficient sharing of physical resources among VMs. | Resource sharing is limited to the host machine. |
| Flexibility | Enables running multiple operating systems on a single physical machine. | Limited to running a single operating system. |
(c) What is “inode”? Explain File and Directory Management of Unix Operating System.
In Unix operating systems, an “inode” (short for index node) is a data structure that represents a file or directory. It contains metadata about the file or directory, such as its size, permissions, ownership, timestamps, and pointers to the data blocks that store the actual file content. The inode acts as a reference to the file or directory.
File Management:
- Each file in Unix is associated with an inode that stores its metadata.
- The inode contains information about the file’s size, permissions, timestamps, and pointers to data blocks.
- The file content is stored in one or more data blocks, and the inode points to these blocks.
- File operations like reading, writing, and modifying the file are performed through the inode.
Directory Management:
- Directories in Unix are also represented by inodes.
- A directory inode contains a list of entries, where each entry maps a filename to an inode number.
- The entries store the filename and the corresponding inode number for the file or subdirectory.
- The inode number is used to access the metadata and data blocks of the file or subdirectory.
OR
Q.5
(a) What is marshalling and unmarshalling?
- Marshalling and unmarshalling are techniques used for data serialization and deserialization.
- Marshalling involves converting data objects into a suitable format for transmission or storage
- While unmarshalling involves reconstructing data objects from their serialized form.
(b) What are components of Linux systems?
The components of a Linux system include:
- Kernel: The core of the operating system that manages system resources, provides essential services, and handles hardware interactions.
- Shell: The command-line interface that allows users to interact with the system by executing commands and running programs.
- File System: The structure and organization of files and directories that allows for data storage and retrieval.
- System Libraries: Collections of pre-compiled functions and code that provide common functionality to applications and programs.
(c) Explain Disk arm scheduling algorithm.
Disk arm scheduling algorithms are used to determine the order in which disk I/O requests are serviced by the disk arm, which is responsible for reading and writing data on the disk.
- FCFS/FIFO (First-Come-First-Served): Requests are serviced in the order they arrive, without considering the location of the requests on the disk. This algorithm can lead to poor performance if there are large differences in seek times between requests.
- SSTF (Shortest Seek Time First): The request with the shortest seek time from the current position of the disk arm is serviced next. This algorithm aims to minimize the total seek time by prioritizing requests that are closest to the current position.
- SCAN: The disk arm starts from one end of the disk and moves towards the other end, servicing requests along the way. Once it reaches the other end, it reverses its direction and starts servicing requests in the opposite direction. This algorithm ensures fairness in servicing requests and avoids indefinite postponement.
- C-SCAN (Circular SCAN): Similar to the SCAN algorithm, the disk arm moves in a linear fashion. However, when it reaches one end of the disk, it immediately returns to the other end without servicing requests in the reverse direction. This reduces the waiting time for requests located at the opposite end of the disk.
- LOOK: The disk arm moves only until it has serviced all the pending requests in its current direction. It then reverses its direction and starts servicing requests in the opposite direction. This algorithm eliminates unnecessary movement to the extremes of the disk, resulting in reduced seek times.
- C-LOOK (Circular LOOK): Similar to the LOOK algorithm, the disk arm moves only until it has serviced all the pending requests in its current direction. However, when it reaches one end, it immediately returns to the other end without servicing requests in the reverse direction. This reduces seek times for requests located at the opposite end of the disk.