IMP Answers
3 Marks
Various Criteria for a good process scheduling algorithm [s22,w22,w21]
- A good process scheduling algorithm should possess various criteria to efficiently manage the execution of processes in a computer system. Some of the key criteria for a good process scheduling algorithm are:
- High CPU Utilization
- High Throughput
- Short Turn Around Time
- Less Waiting Time
- Less Response Time
- Fair Allocation of Resources
Functions of Operating System [s22, s21]
Various Functions of Operating System are :
- Process Management
- Memory Management
- Device Management
- File System Management
- User Interface
- Security
- Networking
- Monitoring and Performance Analysis
Differentiate between Preemption and Non Preemption
OR Differentiate Preemptive and Non Preemptive Scheduling [s22,w22,s21]
| Preemption | Non-Preemption |
|---|---|
| Allows for the interruption of a process | Does not allow for the interruption of a process |
| Process can be forcefully paused or suspended by the operating system | Process continues its execution until it voluntarily yields the CPU or completes its execution |
| Higher priority processes can preempt lower priority processes | Process priorities do not change during execution |
| Used in preemptive scheduling algorithms | Used in non-preemptive scheduling algorithms |
Difference Between Thread and Process [s22,w22]
| Thread | Process |
|---|---|
| Lightweight execution unit within a process | Instance of a program in execution |
| Shares the same memory space with other threads in the same process | Has its own separate memory space |
| Can communicate with other threads directly through shared memory | Requires inter-process communication mechanisms for communication |
| Multiple threads can exist within a single process | Each process has its own independent execution |
RAID ( list or features ) [ s22, w21 ]
- RAID 0: Striping - Increased performance
- RAID 1: Mirroring - Data redundancy
- RAID 2: Hamming code - Error correction
- RAID 3: Byte-level striping - Parallel processing
- RAID 4: Block-level striping with dedicated parity disk - High data transfer rates
- RAID 5: Block-level striping with distributed parity - Data redundancy, improved performance
- RAID 6: Block-level striping with double distributed parity - Enhanced fault tolerance
Access Control list [s22, s21, w21, w20]
- Access Control List (ACL) is a security mechanism that specifies the permissions granted or denied to individual users or groups for accessing a resource.
- ACLs define the specific permissions granted or denied to users or groups for accessing a resource.
- ACLs enable administrators to set access rights at the individual user or group level, providing flexibility in managing resource access.
- ACLs help protect resources by ensuring that only authorized users or groups can access them, enhancing overall system security.
One question from Security (Attacks, diff. between. security and protection )
Virtualization. Need ? [s21,w20]
Virtualization is the process of creating virtual versions of computer resources, such as hardware, operating systems, storage devices, or network resources. It allows multiple virtual environments to run on a single physical system
- Virtualization allows efficient utilization of hardware by running multiple virtual machines on a single physical server.
- Virtualization enables easy scaling of resources based on changing demands, providing flexibility in resource allocation.
- Virtualization ensures strong isolation between virtual machines, enhancing security by preventing interference and unauthorized access.
Difference between [s21,w20]
- Multitasking and Multiprogramming
| Multitasking | Multiprogramming |
|---|---|
| When a single resource is used to process multiple tasks then it is multitasking. | When multiple programs execute at a time on a single device, it is multiprogramming. |
| The process resides in the same CPU. | The process resides in the main memory. |
| It is time sharing as the task assigned switches regularly. | It uses batch OS. The CPU is utilized completely while execution. |
| Multitasking follows the concept of context switching. | The processing is slower, as a single job resides in the main memory while execution. |
- Multiprocessing and Multiprogramming
| Multiprocessing | Multiprogramming |
|---|---|
| Involves the use of multiple processors or cores to execute multiple tasks or programs simultaneously | Involves running multiple programs on a single processor or core |
| Provides true parallelism by executing tasks or programs simultaneously on different processors or cores | Utilizes time-sharing techniques to switch between programs and provide the illusion of concurrent execution |
| Typically requires specialized hardware support, such as multiple processors or cores | Can be implemented on a single processor or core with the help of scheduling algorithms |
| Examples include systems with multiple processors or cores, such as high-performance servers or supercomputers | Commonly used in desktop and server operating systems to efficiently run multiple programs |
Diff. between User Level Thread and Kernel Level Thread [ w22,w21 ]
| User-Level Threads | Kernel-Level Threads |
|---|---|
| Managed by user-level thread library | Managed by the operating system kernel |
| Lightweight and created by the application | Kernel-level threads are heavier and created by the operating system |
| Context switching is faster as it doesn't involve kernel intervention | Context switching involves kernel intervention and is comparatively slower |
| If one user-level thread blocks, it blocks the entire process | Kernel-level threads can be scheduled independently |
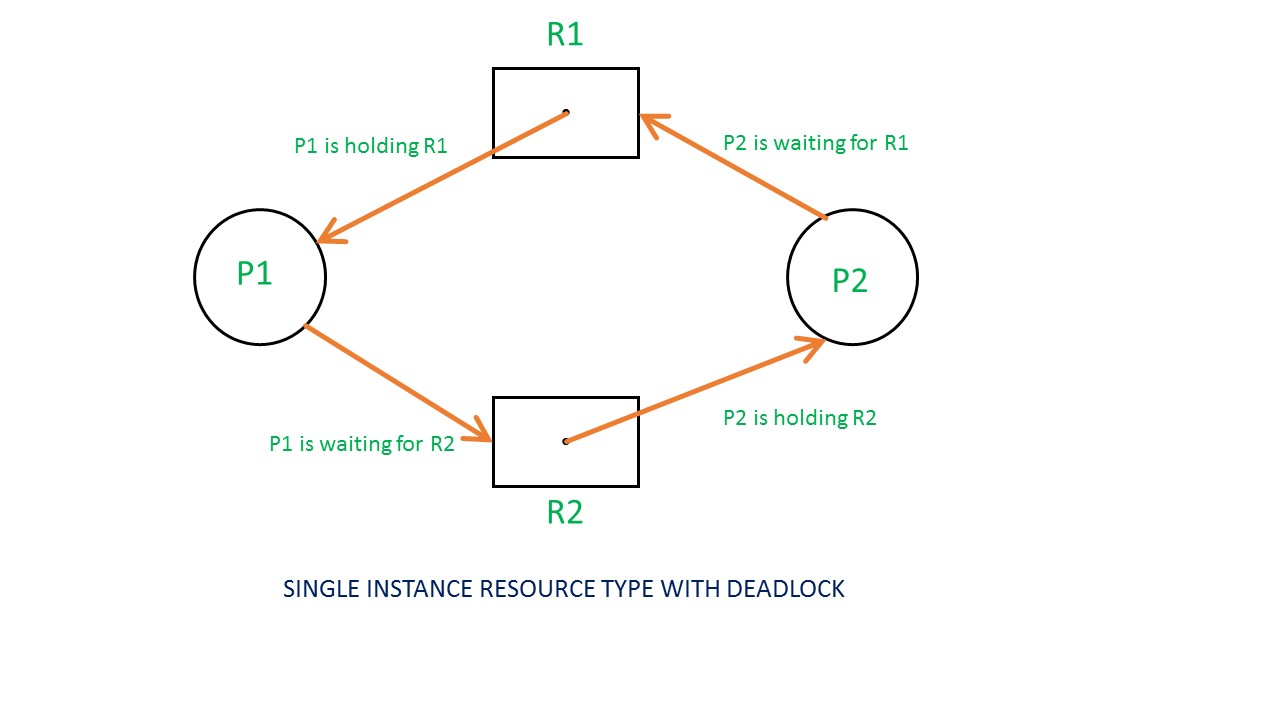
Resource Allocation Graph [w22,w21]
- Resource Allocation Graph is a graphical representation used in operating systems to describe the allocation of resources to processes
- It helps in analyzing resource allocation and detecting potential deadlocks in a system.
- A cycle in the resource allocation graph signifies a potential deadlock situation, allowing for the detection and prevention of deadlocks.
- If a process is using a resource, an arrow is drawn from the resource node to the process node. If a process is requesting a resource, an arrow is drawn from the process node to the resource node.
- Example :
Segmentation [w22,w21]
- Segmentation is a memory management technique in which the memory is divided into the variable size parts. Each part is known as a segment which can be allocated to a process.
- This allows for efficient memory allocation as each segment can be allocated to a process based on its specific memory requirements.
- Segmentation facilitates memory protection by assigning appropriate access permissions to each segment. This ensures that processes can only access the segments they are authorized to, enhancing security and preventing unauthorized memory access.
4 Marks
Pages and Frames
Pages:
- Pages are fixed-sized blocks of memory used in the paging memory management technique.
- The logical memory of a process is divided into pages, which are typically of equal size.
- The size of a page is determined by the hardware and operating system, often referred to as the page size.
Frames:
- Frames are also fixed-sized blocks of physical memory.
- The physical memory is divided into frames, which are typically of the same size as the pages.
- Each frame corresponds to a fixed-sized portion of the physical memory, which can store a page of memory.
Mapping Pages to Frames:
- The logical pages of a process are mapped to physical frames through a page table.
- The page table maintains the mapping between the logical pages and the corresponding physical frames.
- The operating system handles the translation of logical addresses to physical addresses using the page table.
Essential Properties/Features of [s22,s21,w20]
Batch
- Batch operating systems schedule and manage multiple jobs (tasks) to maximize resource utilization and efficiency. They prioritize jobs based on criteria such as job submission time, priority, and available resources.
- Batch operating systems are designed to execute jobs automatically, without requiring user intervention.
- Batch operating systems are optimized for offline processing, where input data is prepared in advance, and the system processes the data without requiring immediate user interaction.
- Batch operating systems aim to maximize resource utilization by efficiently allocating system resources such as CPU time, memory, and I/O devices across multiple jobs.
Time Sharing
- Time division: CPU time is divided into small time intervals.
- Process switching: Rapid switching between multiple processes.
- Interactive environment: Support for multiple users concurrently.
- Fairness: Each user or process receives a fair share of CPU time.
- Responsiveness: Provides a responsive environment for interactive tasks.
Real Time
- Real-time systems must meet specific timing constraints and deadlines.
- Real-time systems provide guaranteed response times and bounded execution times, ensuring reliable and consistent performance.
- Tasks in real-time systems are assigned priorities based on their criticality and timing requirements.
- Real-time systems employ scheduling algorithms that prioritize tasks and ensure timely execution of critical tasks.
- Real-time systems aim to minimize the time between an event occurrence and the system's response to it.
Distributed
- Distributed systems enable sharing of hardware, software, and data resources across multiple nodes or machines.
- Distributed systems can easily scale by adding or removing nodes, allowing for increased performance and capacity.
- Distributed systems support concurrent execution of multiple tasks or processes across different nodes, enabling parallel processing.
- Distributed systems incorporate security mechanisms to protect data and resources from unauthorized access or breaches.
- Distributed systems provide transparency to users and applications, abstracting the underlying complexities of the distributed infrastructure.
What is Thread ? [s22,s21,w21,w20]
A thread is a lightweight, independent unit of execution within a process that can be scheduled and managed by the operating system.
Classic Thread Model
Thread Scheduling
- Thread scheduling determines the order and timing of thread execution.
- It is based on thread priorities, policies, and synchronization mechanisms.
- Scheduling policies can be preemptive or non-preemptive.
- The scheduler performs context switching and aims for fairness and efficiency in CPU time allocation.
- Synchronization mechanisms like locks and semaphores are used to coordinate thread execution.
Define [s22,w22,w21,w20]
Race condition
Race condition refers to a situation in concurrent programming where the behavior of a program is dependent on the timing and order of execution of threads, leading to unpredictable and unintended outcomes.
Critical section
A critical section is a specific part of a program where shared resources or data are accessed and manipulated, requiring exclusive execution to prevent race conditions
Mutual exclusion
Mutual exclusion is a property or mechanism that allows only one thread or process to access a shared resource at any given time, preventing concurrent access and ensuring data integrity.
Semaphores
Semaphores are synchronization objects used in concurrent programming to control access to shared resources. They act as counters and can be used to coordinate and synchronize the execution of multiple threads or processes by allowing them to wait for or signal certain conditions.
Bounded Waiting.
Bounded waiting is a property in concurrent systems that guarantees that a process will eventually be granted access to a resource, as there is a limit on the number of times a process can be denied access. It ensures fairness and prevents indefinite blocking or starvation of a process.
Priority Scheduling [s22]
- Priority scheduling is a CPU scheduling algorithm where each process is assigned a priority value, and the CPU is allocated to the process with the highest priority.
- Processes with same priority are executed on first come first served basis.
- Preemptive and Non-Preemptive: Priority scheduling can be either preemptive or non-preemptive.
- Priority scheduling can lead to starvation, where lower-priority processes may not receive sufficient CPU time if higher-priority processes constantly occupy the CPU.
- To mitigate this, aging techniques or priority adjustments may be used to prevent indefinite starvation.
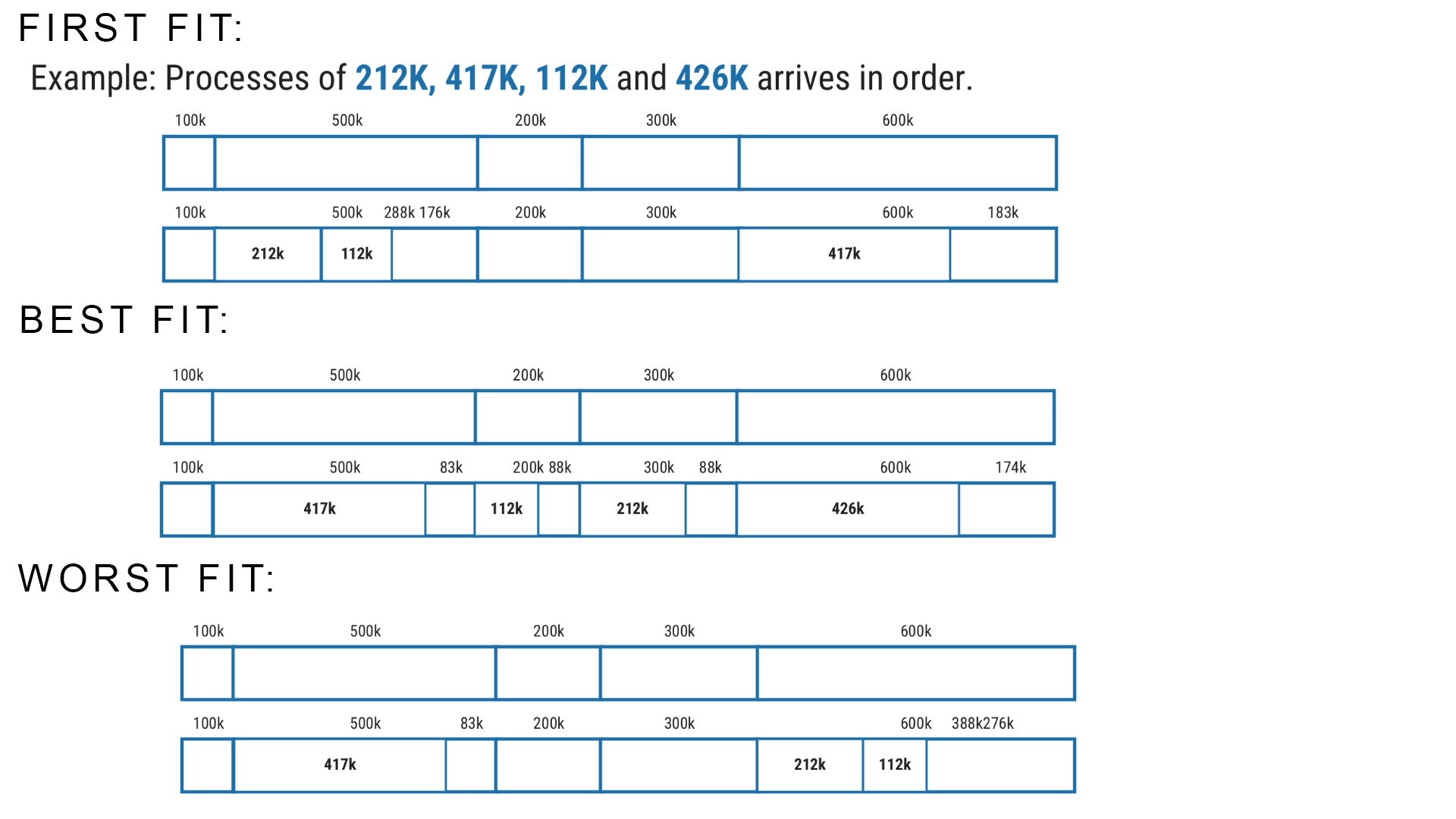
Memory Allocation Technique : First, Best, Worst [s22,w22,s21,w21]
First Fit: First fit is a memory allocation algorithm that searches the memory partitions from the beginning and allocates the first available partition that is large enough to accommodate the process.
Best Fit: Best fit is a memory allocation algorithm that searches the memory partitions and allocates the smallest partition that is large enough to accommodate the process.
Worst Fit: Worst fit is a memory allocation algorithm that searches the memory partitions and allocates the largest available partition to the process.
Example :
Fragmentation [s21,w22,w21]
- diff. between External and Internal Fragmentation
- Solution to both type of Fragmentation
Fragmentation
Fragmentation is an unwanted problem in the operating system in which the processes are loaded and unloaded from memory, and free memory space is fragmented (holes). Processes can't be assigned to memory blocks due to their small size, and the memory blocks stay unused.
The conditions of fragmentation depend on the memory allocation system. As the process is loaded and unloaded from memory, these areas are fragmented into small pieces of memory that cannot be allocated to incoming processes. It is called fragmentation.
Difference Between Internal and External Fragmentation
| Internal Fragmentation | External Fragmentation |
|---|---|
| When a process is allocated to a memory block, and if the process is smaller than the amount of memory requested, a free space is created in the given memory block. Due to this, the free space of the memory block is unused, which causes internal fragmentation. | External fragmentation happens when a dynamic memory allocation method allocates some memory but leaves a small amount of memory unusable. The quantity of available memory is substantially reduced if there is too much external fragmentation. There is enough memory space to complete a request, but it is not contiguous. It's known as external fragmentation. |
| Internal fragmentation occurs with paging and fixed partitioning. | External fragmentation occurs with segmentation and dynamic partitioning. |
| The solution of internal fragmentation is the best-fit. | The solution to external fragmentation is compaction and paging. |
Solution for Internal Fragmentation
- The problem of internal fragmentation may arise due to the fixed sizes of the memory blocks. It may be solved by assigning space to the process via dynamic partitioning. Dynamic partitioning allocates only the amount of space requested by the process. As a result, there is no internal fragmentation.
Solution for External Fragmentation
- This problem occurs when you allocate RAM to processes continuously. It is done in paging and segmentation, where memory is allocated to processes non-contiguously. As a result, if you remove this condition, external fragmentation may be decreased.
- Compaction is another method for removing external fragmentation. External fragmentation may be decreased when dynamic partitioning is used for memory allocation by combining all free memory into a single large block. The larger memory block is used to allocate space based on the requirements of the new processes. This method is also known as defragmentation.
Virtualization [s21,w22,w21,w20]
- Benefits
- Virtual and Non Virtual Machines
Virtualization
- Virtualization is a technology that allows you to use one physical computer to run multiple virtual computers or operating systems at the same time.
- It creates a virtual version of a computer, known as a virtual machine (VM), which acts like a real computer with its own operating system and applications.
- Imagine you have a powerful computer, and with virtualization, you can divide it into several smaller computers, each with its own resources like memory, processing power, and storage. These virtual machines can run different operating systems, such as Windows, Linux, or macOS, depending on your needs.
Benefits of Virtualization
- Reduced capital and operating costs.
- Increased IT productivity, efficiency, agility and responsiveness.
- Faster provisioning of applications and resources.
- Greater business continuity.
- Simplified data centre management.
- Improvised security by separating several applications to several containers.
Virtual Machine
A virtual machine is an emulation of a computer system within a physical machine. It enables the execution of multiple operating systems simultaneously on a single physical host machine.
A virtual machine provides an abstraction layer between the underlying hardware and the guest operating system(s) running on top of it. This abstraction allows different operating systems to run on the same physical machine with their own virtualized hardware resources isolated.
VMs can be assigned specific amounts of CPU, memory, storage, and other resources. The host system manages the allocation and scheduling of these resources among the VMs.
Non Virtual Machine
The term "non-virtual machine" generally refers to a traditional physical machine, where the operating system runs directly on the physical hardware without virtualization.
There is no layer of abstraction or virtualization between the operating system and the underlying hardware.
The operating system directly interacts with the physical resources of the machine, such as CPU, memory, storage, and peripherals.
Process States [s21,w22,w20]
- Different Stages with various queues
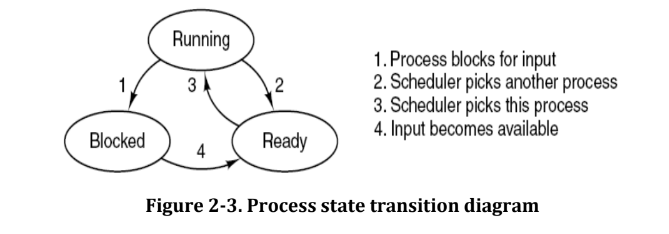
Process State
- The state of a process is defined by the current activity of that process.
- During execution, process changes its state.
- The process can be in any one of the following three possible states.
- Running (actually using the CPU at that time and running).
- Ready (runnable; temporarily stopped to allow another process run).
- Blocked (unable to run until some external event happens).
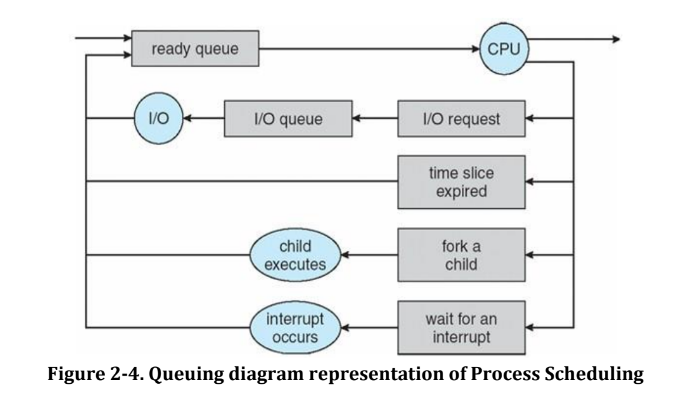
Different Stages with Various Queues
- As the process enters the system, it is kept into a job queue.
- The processes that are ready and are residing in main memory, waiting to be executed are kept in a ready queue.
- This queue is generally stored as a linked list.
- The list of processes waiting for a particular I/O device is called a device queue
- Each device has its own queue. Figure shows the queuing diagram of processes
- In the figure each rectangle represents a queue.
- here are following types of queues
- Job queue : set of all processes in the system
- Ready queue : set of processes ready and waiting for execution
- Set of device queues : set of processes waiting for an I/O device
- The circle represents the resource which serves the queues and arrow indicates flow of processes.
- A new process is put in ready queue. It waits in the ready queue until it is selected for execution and is given the CPU.
Deadlock [w22,w21,w20]
- Conditions for deadlock
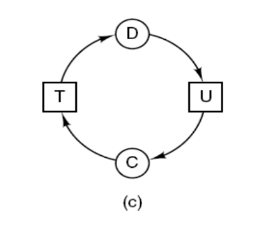
Deadlock
- A set of processes is deadlocked if each process in the set is waiting for an event that only another process in the set can cause.
- Suppose process D holds resource T and process C holds resource U.
- Now process D requests resource U and process C requests resource T but none of process will get this resource because these resources are already hold by other process so both can be blocked, with neither one be able to proceed, this situation is called deadlock.
Unix Commands [w22,w21,w20]
grep
- It selects and prints the lines from a file which matches a given string or pattern.
- Syntax:- grep [options] pattern [file]
- Flags:
| -i | Ignore case distinctions |
|---|---|
| iv | Invert the sense of matching, to select non-matching lines. |
| -w | Select only those lines containing matches that form whole words. |
| -x | Select only matches that exactly match the whole line. |
| -c | print a count of matching lines for each input file. |
- Example: $ grep -i "UNix" file.txt
sort
- It is used to sort the lines in a text file.
- Syntax:- sort [options] filename
- Flags:
| -b | Ignores spaces at beginning of the line | | --- | --- | | -c | Check whether input is sorted; do not sort | | -r | Sorts in reverse order | | -u | If line is duplicated only display once | | -r | Reverse the result of comparisons. | - Example : $ sort -r data.txt
chmod
- chmod command allows you to alter / Change access rights to files and directories.
- Syntax:- chmod [options] [MODE] FileName
- Flags:
| Options | Description | | --- | --- | |-R| Apply the permission change recursively to all the files and directories within the specified directory. | |-v| It will display a message for each file that is processed. while indicating the permission change that was made. | |-c| It works same as-vbut in this case it only displays messages for files whose permission is changed. | |-f| It helps in avoiding display of error messages. | |-h| Change the permissions of symbolic links instead of the files they point to. | - chmod can be used in symbolic or octal mode.
- Example :
- Symbolic :
chmod u+rwx [file_name] - Octal :
chmod 674 [file_name]
- Symbolic :
mkdir
- This command is used to create a new directory
- Syntax :- mkdir [options] directory
- Flags :
| -m | Set permission mode (as in chmod) | | --- | --- | | -p | No error if existing, make parent directories as needed. | | -v | Print a message for each created directory | - Example : $ mkdir aaa
cat
- It is used to create, display and concatenate file contents.
- Syntax : - cat [options] [FILE]…
- Flags :
| -A | Show All. | | --- | --- | | -b | Omits line number for blank space in the output | | -e | A $ character will be printed at the end of each line prior to a new line. | | -E | Displays a $ (dollar sign) at the end of each line. | | -n | Line numbers for all the output lines. | | -s | If the output has multiple empty lines it replaces it with one empty line. | | -T | Displays the tab characters in the output. | | -v | Non-printing characters (with the exception of tabs, new-lines and form-feeds) are printed visibly. | - Example : cat file1.c
touch
- It is used to create a file without any content. The file created using touch command is empty. This command can be used when the user doesn’t have data to store at the time of file creation.
- Syntax : touch file1_name file2_name file3_name
- Example : touch bash.txt
rm
- It is used to remove/delete the file from the directory. Deleted file can’t be recovered. rm can’t delete the directories. If we want to remove all the files from the particular directory we can use the * symbol.
- Syntax :- rm [options..] [file | directory]
- Flags :
| -f | Ignore nonexistent files, and never prompt before removing. | | --- | --- | | -i | Prompt before every removal. | - Example :
- rm *
- rm file1.txt
7 marks
Process, Process States, Process Control Block, Process Creation and Termination with all parameters [MIMP] [s22,s21,w22,w21,w20]
Process:
- Process is a program under execution.
- It is an instance of an executing program, including the current values of the pro- gram counter, registers & variables.
- Process is an abstraction of a running program.
Process States
- The state of a process is defined by the current activity of that process.
- During execution, process changes its state.
- The process can be in any one of the following three possible states.
- Running (actually using the CPU at that time and running).
- Ready (runnable; temporarily stopped to allow another process run).
- Blocked (unable to run until some external event happens).
Different Stages with Various Queues
- As the process enters the system, it is kept into a job queue.
- The processes that are ready and are residing in main memory, waiting to be executed are kept in a ready queue.
- This queue is generally stored as a linked list.
- The list of processes waiting for a particular I/O device is called a device queue
- Each device has its own queue. Figure shows the queuing diagram of processes
- In the figure each rectangle represents a queue.
- here are following types of queues
- Job queue : set of all processes in the system
- Ready queue : set of processes ready and waiting for execution
- Set of device queues : set of processes waiting for an I/O device
- The circle represents the resource which serves the queues and arrow indicates flow of processes.
- A new process is put in ready queue. It waits in the ready queue until it is selected for execution and is given the CPU.
Process Control Block
- A Process Control Block (PCB) is a data structure maintained by the operating system for every process.
- PCB is used for storing the collection of information about the processes.
- The PCB is identified by an integer process ID (PID).
- A PCB keeps all the information needed to keep track of a process.
- The PCB is maintained for a process throughout its lifetime and is deleted once the process terminates.
- The architecture of a PCB is completely dependent on operating system and may contain different information in different operating systems.
- PCB lies in kernel memory space.
- To implement the process model, the operating system maintains a table (an array of structures) called the process table, with one entry per process, these entries are known as Process Control Block.
- Fields of Process Control Block
- Process ID - Unique identification for each of the process in the operating system.
- Process State - The current state of the process i.e., whether it is ready, running, waiting.
- Pointer - A pointer to the next PCB in queue.
- Priority - Priority of a process.
- Program Counter - Program Counter is a pointer to the address of the next instruction to be executed for this process.
- CPU registers - Various CPU registers where process need to be stored for execution for running state.
- IO status information - This includes a list of I/O devices allocated to the process.
- Accounting information - This includes the amount of CPU used for process execution, time limits etc.
- Memory limits – Memory limits assigned to the process
- List of open Files – The files that the process is using
- Memory management information - Information about page tables/segment tables
Process Creation and Termination
Process Creation
- System initialization
- At the time of system (OS) booting various processes are created
- Foreground and background processes are created
- Execution of a process creation system call (fork) by running process
- Running process will issue system call (fork) to create one or more new process to help it.
- A user request to create a new process
- Start process by clicking an icon (opening word file by double click) or by typing command.
- Initialization of batch process
- Applicable to only batch system found on large mainframe
Process Termination
- Normal exit (voluntary)
- Terminated because process has done its work
- Error exit (voluntary)
- The process discovers a fatal error e.g. user types the command cc foo.c to compile the program foo.c and no such file exists, the compiler simply exit.
- Fatal error (involuntary)
- An error caused by a process often due to a program bug e.g. executing an illegal instruction, referencing nonexistent memory or divided by zero.
- Killed by another process (involuntary)
- A process executes a system call telling the OS to kill some other process using kill system call.
Semaphore (with code) [MIMP] [s22,w22,w21,w20]
- Producers Consumer
- Readers writers
- Dining Philosopher
Semaphore
- A semaphore is a variable that provides an abstraction for controlling access of a shared resource by multiple processes in a parallel programming environment.
- There are 2 types of semaphores:
- Binary semaphores: - Binary semaphores have 2 methods associated with it (up, down / lock, unlock). Binary semaphores can take only 2 values (0/1). They are used to acquire locks.
- Counting semaphores: - Counting semaphore can have possible values more than two.
Producer Consumer Problem using semaphore
#define N 4
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer(void) {
int item;
while (true) {
item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer(void) {
int item;
while (true) {
down(&full);
down(&mutex);
item = remove_item(item);
up(&mutex);
up(&empty);
consume_item(item);
}
}Readers Writer Using Semaphore
typedef int semaphore;
semaphore mutex=1; //control access to reader count
semaphore db=1; //control access to database
int reader_count=0; //number of processes reading database
void Reader (void){
while (true) {
wait(&mutex); //gain access to reader count
reader_count=reader_count+1; //increment reader counter
if(reader_count==1) //if this is first process to read DB
{
wait(&db) //prevent writer process to access DB
}
signal(&mutex) //allow other process to access reader_count
read_database();
wait(&mutex); //gain access to reader count
reader_count=reader_count-1; //decrement reader counter
if(reader_count==0) //if this is last process to read DB
{
signal(&db) //leave the control of DB, allow writer process
}
signal(&mutex) //allow other process to access reader_count
use_read_data(); //use data read from DB (non-critical)
}
}
void Writer (void)
{
while (true) {
create_data(); //create data to enter into DB (non-critical)
wait(&db); //gain access to DB
write_db(); //write information to DB
signal(&db); //release exclusive access to DB
}
}Dining Philosopher using Semaphore
#define N 5 //no. of philosophers
#define LEFT (i+N-1)%5 //no. of i’s left neighbor
#define RIGHT (i+1)%5 //no. of i’s right neighbor
#define THINKING 0 //Philosopher is thinking
#define HUNGRY 1 //Philosopher is trying to get forks
#define EATING 2 //Philosopher is eating
typedef int semaphore; //semaphore is special kind of int
int state[N]; //array to keep track of everyone’s state
semaphore mutex=1; //mutual exclusion for critical region
semaphore s[N]; //one semaphore per philosopher
void take_forks (int i) //i: philosopher no, from 0 to N-1
{
wait(&mutex); //enter critical region
state[i]=HUNGRY; //record fact that philosopher i is hungry
test(i); //try to acquire 2 forks
signal(&mutex); //exit critical region
wait(&s[i]); //block if forks were not acquired
}
void test(i) // i: philosopher no, from 0 to N-1
{
if(state[i]==HUNGRY && state[LEFT]!=EATING && state[RIGHT]!=EATING)
{
state[i]=EATING;
signal(&s[i]);
}
}
void put_forks(int i) //i: philosopher no, from 0 to N-1
{
wait(&mutex); //enter critical region
state[i]=THINKING; //philosopher has finished eating
test(LEFT); //see if left neighbor can now eat
test(RIGHT); // see if right neighbor can now eat
signal(&mutex); // exit critical region
}
void philosopher (int i) //i: philosopher no, from 0 to N-1
{
while(true)
{
think(); //philosopher is thinking
take_forks(i); //acquire two forks or block
eat(); //eating spaghetti
put_forks(i); //put both forks back on table
}
}Monitor
- A monitor is a special tool used in computer programming to make sure that multiple processes or threads can safely share resources and coordinate their actions. It acts like a "guard" that allows only one process to be inside at a time.
Producer Consumer using Monitor
monitor boundbuffer; //start of monitor
char buffer[N]; // N slots
int nextin,nextout; // buffer pointers
int count; // number of items in buffers
int notfull, notempty; // condition variables
void append(char a) // monitor procedure public
{
if (count == N) //if buffer is full
cwait(notfull); // avoid overflow
buffer[nextin]=a;
nextin=(nextin+1)%N;// next slot in buffer
count++; // An item is added in buffer
csignal(notempty); //resume if consumes waiting
}
void take(char a) // monitor procedure public
{
if (count==0) // if buffer is empty
cwait(notempty); // avoid underflow
a = buffer[nextout];
nextout = (nextout+1)%N; //next slot in buffer
count --; // An item is removed from buffer
csignal(notfull); // resume any waiting producer
}
{ //initialization
nextin=nextout=count=0; //initially buffer empty
}
void main()
{
pasbegin(producer, consumer);
}Deadlock in Detail (Characteristic, structure, recovery )
Deadlock refers to a situation in a computer system where two or more processes are unable to proceed further because each process is waiting for a resource that is held by another process in the same set of processes.
Characteristics of Deadlock:
- Mutual Exclusion: At least one resource must be held in a non-sharable mode, preventing other processes from accessing it simultaneously.
- Hold and Wait: Processes hold resources while waiting for additional resources, causing resource utilization inefficiency.
- No Preemption: Resources cannot be forcibly taken away from a process, even if it is not actively using them.
- Circular Wait: A circular chain of processes exists, where each process is waiting for a resource held by another process in the chain.
Structure of Deadlock:
- Resources: The system consists of various resources that processes can request, such as memory, CPU time, files, or devices.
- Processes: Multiple processes are running concurrently and compete for resources.
- Resource Allocation Graph: Deadlock can be visualized using a resource allocation graph, which shows the relationships between processes and resources.
Deadlock Recovery: There are two common approaches to recover from deadlock:
- Deadlock Detection and Termination: The system periodically checks for the existence of a deadlock. If a deadlock is detected, one or more processes involved in the deadlock are terminated to break the deadlock. The terminated processes release their held resources, allowing other processes to proceed.
- Deadlock Avoidance (Explained Below in detail)
Deadlock Avoidance [MIMP] [s22,s21,w22]
Deadlock avoidance is another approach to handle deadlocks in a system. It involves employing resource allocation strategies that dynamically decide whether granting a resource request would potentially lead to a deadlock.
Bankers Algorithm
The Banker's algorithm is a resource allocation and deadlock avoidance algorithm used in operating systems. It works by analyzing the current resource allocation and future resource request scenarios to determine whether granting a request will keep the system in a safe state (i.e., free from deadlock).
- System State: The Banker's algorithm maintains information about the current state of the system, including the available resources, maximum resource requirements of each process, and the allocated resources.
- Safety Algorithm: The algorithm performs a safety check before granting a resource request. It simulates the allocation of resources and checks if there is a sequence of resource allocations that can satisfy all processes without resulting in a deadlock. If such a safe sequence exists, the request is considered safe and can be granted.
- Resource Request: When a process requests additional resources, the Banker's algorithm checks if granting the request will keep the system in a safe state. It checks if the requested resources, when added to the current allocation, still allow for a safe sequence of resource allocation.
- Resource Allocation: If granting the resource request will not result in an unsafe state or deadlock, the Banker's algorithm allocates the requested resources to the process. Otherwise, the request is postponed until it can be granted safely.
Deadlock Prevention [s21]
Deadlock prevention is to deny at least one of the 4 conditions for deadlock.
Deadlock prevention is a technique used to ensure that a system avoids reaching a deadlock state. It focuses on breaking one or more of the necessary conditions for deadlock to occur. The following methods are commonly used for deadlock prevention:
- Mutual Exclusion:
- Ensure that resources are not shareable and can only be accessed by one process at a time.
- Avoids the possibility of deadlock due to conflicting resource access.
- Mutual exclusion cannot be denied so it is customary to prevent one of the remaining 3 conditions.
- Hold and Wait:
- Processes must request and acquire all required resources before execution.
- Avoids the possibility of deadlock caused by a process holding resources and waiting for others.
- These are basically two implementation:
- The process requests all needed resources prior to its execution
- The process requests resources incrementally during execution but releases all its resources when it encounters denial of one resource.
- No Preemption:
- Resources cannot be forcefully taken away from a process.
- Avoids the possibility of deadlock caused by a process holding resources indefinitely.
- This deadlock condition of no preemption can be denied by allowing preemption, that is done by authorizing the system to revoke ownership of certain resources from blocked process.
- Circular Wait:
- Implement a resource allocation hierarchy to avoid circular dependency.
- Processes request resources in a predefined order, eliminating the circular wait condition.
- If a process P1 has been allocated a resource Ri, then if another process P2 another resource Rj; The resource Rj is allocated to process P2 only if i<j. So, that there is no circular-wait on resources.
Paging [MIMP] [s22,s21,w22]
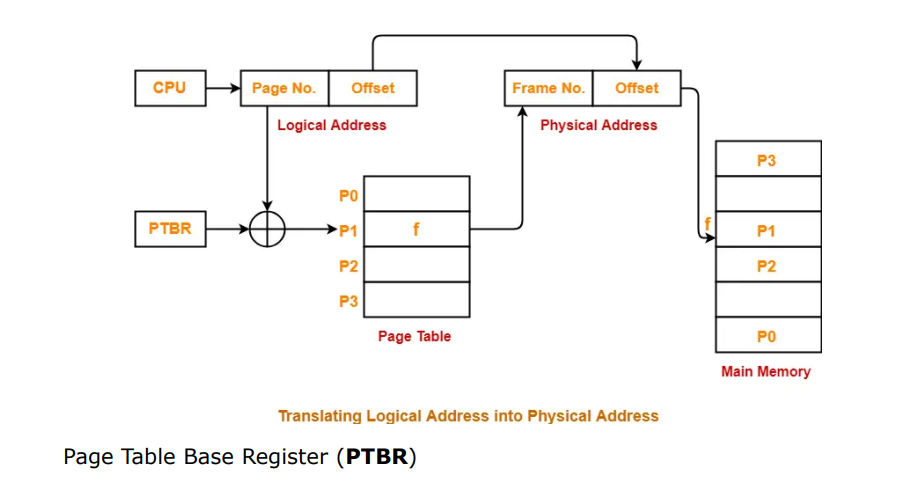
Paging is a memory management technique used in computer systems to efficiently manage and allocate memory. It divides the physical memory into fixed-sized blocks called pages and the logical memory into fixed-sized blocks called page frames.
Paging techniques
Paging techniques refer to different methods or algorithms used for managing and organizing pages in a virtual memory system. These techniques determine how pages are allocated, accessed, and replaced in the main memory.
- Demand Paging: This technique involves bringing pages into memory only when they are needed, rather than loading the entire process into memory at once.
- Page Replacement Algorithms: These algorithms determine which pages to remove from memory when new pages need to be loaded.
- Page Table Organization: The page table is a data structure used by the operating system to keep track of the virtual-to-physical address mappings.
- The page size is the unit of memory allocation in the paging system. Different page sizes can be chosen based on factors like system architecture, application requirements, and performance considerations.
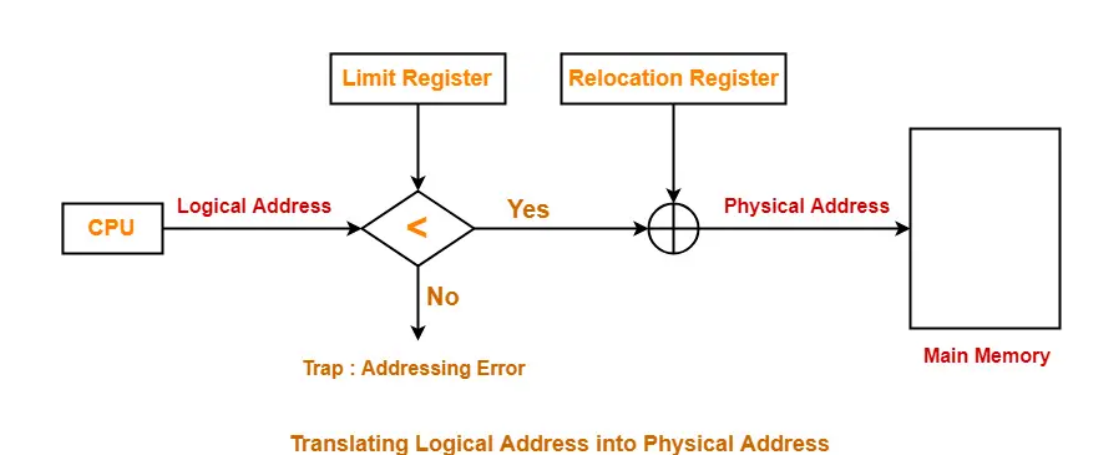
Conversion of Virtual Address to Physical Address (TLB)
- CPU always generates a logical address.
- A physical address is needed to access the main memory.
- The translation scheme uses two registers that are under the control of operating system.
- Relocation Register : Relocation Register stores the base address or starting address of the process in the main memory.
- Limit Register : Limit Register stores the size or length of the process.
- Then CPU generated physical address, if the physical address is greater than or less than limit than a trap is generated. Physical address must be within range limit.
Virtual Address to Physical Address (Paging)
Virtual Address to Physical Address (Paging) (with TLB)
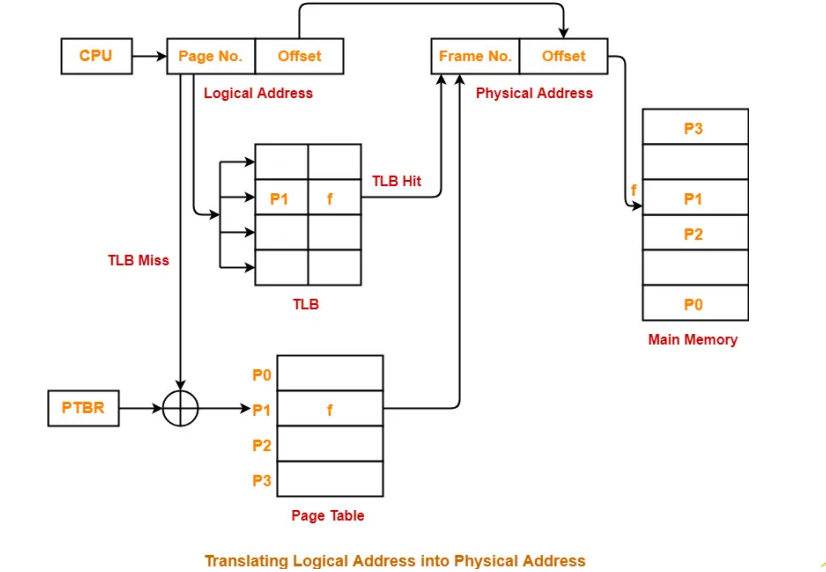
- The Translation Lookaside Buffer (TLB) plays a significant role in speeding up this address translation process.
- TLB is a small, high-speed cache component located between the CPU and the main memory
- When the CPU generates a virtual address during program execution, it first checks the TLB for a matching entry. If a match is found than it is called TLB hit, else it is TLB miss. In case of TLB hit physical address is retrieved directly from the TLB buffer.
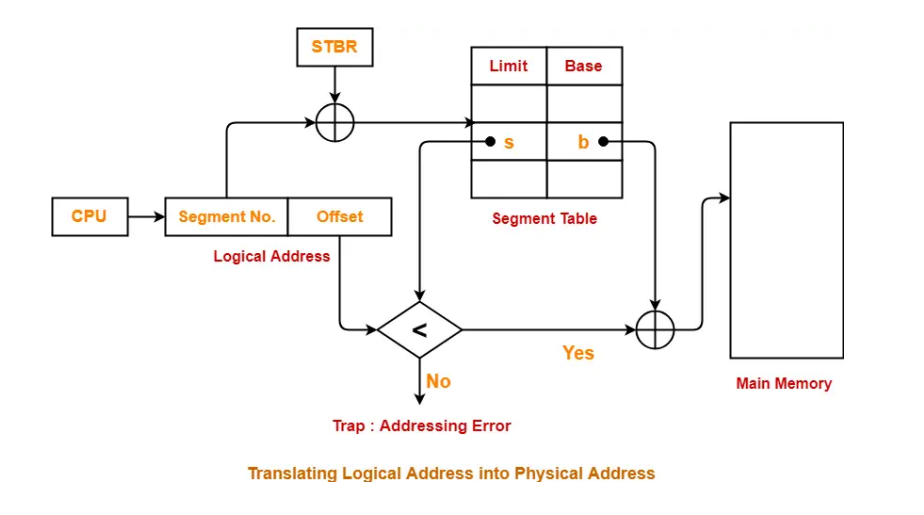
Virtual Address to Physical Address (Segmentation)
Page Fault ?
When a process accesses a page that is not present in the memory, a page fault occurs. The operating system then retrieves the required page from the secondary storage and brings it into the memory.
Demand Paging
- Demand Paging suggests keeping all pages of the frames in the secondary memory until they are required. In other words, it says that do not load any page in the main memory until it is required.
- Whenever any page is referred for the first time in the main memory, then that page will be found in the secondary memory.
- Demand paging is closely related to the concept of virtual memory, where the logical address space of a process is larger than the physical memory available.
- In demand paging, when the main memory is full, and a new page needs to be loaded, a page replacement algorithm selects a victim page to be replaced.
Short Note on RAID [w22,w20]
RAID (Redundant Array of Independent Disks) is a storage technology that combines multiple physical disk drives into a single logical unit to improve performance, reliability, or both.
- Data Striping: RAID uses data striping, which divides data into small blocks and distributes them across multiple drives in the array. This parallelizes data access and improves read and write performance.
- Redundancy: RAID provides redundancy by using various techniques such as mirroring (RAID 1) or parity (RAID 5). Redundancy ensures data integrity and allows for data recovery in case of disk failures.
- Performance Improvement: RAID can significantly enhance read and write performance by distributing data across multiple drives, enabling multiple disk heads to access data simultaneously.
- Fault Tolerance: RAID offers fault tolerance, allowing the array to continue functioning even if one or more disks fail. In redundant RAID levels (e.g., RAID 1, RAID 5), the array can reconstruct the lost data using the redundant information.
- Data Protection: RAID provides data protection against disk failures. When a disk fails, the system can rebuild the data using the redundancy information stored on other drives.
- Different RAID Levels: RAID offers various levels or configurations, including RAID 0, RAID 1, RAID 5, RAID 10, and more. Each RAID level has its own characteristics, such as performance, fault tolerance, and storage efficiency.
- Applications: RAID is commonly used in servers, storage systems, and high-performance computing environments where data availability, performance, and reliability are crucial.
Numerical from [Page Replacement, Disk Scheduling, CPU Scheduling] [w21,w20]
Any one Page Replacement Algorithm in Detail [s22]
First-In-First-Out (FIFO) -
- The First-In-First-Out (FIFO) page replacement algorithm is a simple and intuitive approach used in operating systems to manage memory pages.
- Initially, all page frames are empty. As the process begins, pages are brought into memory and allocated to available page frames.
- When a new page needs to be loaded into memory, but all page frames are already occupied, the FIFO algorithm selects the oldest page in memory for replacement. The selected page is the one that has been in memory the longest, as it was the first to enter the queue.
- To implement FIFO, a data structure such as a queue or a circular buffer is used to maintain the order in which pages entered memory. Each time a page is brought into memory, it is added to the end of the queue.
- If a requested page is already in memory, there is no page fault, and the process can continue without interruption. However, if a requested page is not in memory (a page fault occurs), the FIFO algorithm replaces the page at the front of the queue with the new page.
- It suffers from a drawback known as the "Belady's Anomaly." This anomaly refers to situations where increasing the number of available page frames actually leads to an increase in page faults.
- FIFO does not consider the frequency or recency of page accesses. As a result, it can lead to external fragmentation.